

JAKARTA, cssmayo.com – In an era where data is called “the new oil,” having massive volumes of information means nothing if you can’t access, trust, or analyze it effectively. Data Architecture is the blueprint that transforms raw data chaos into structured, reliable assets that power insights, drive decisions, and fuel AI models. In this guide, I’ll break down the principles, frameworks, and real-world lessons for building Data Architecture that actually works—not just looks good on a whiteboard.
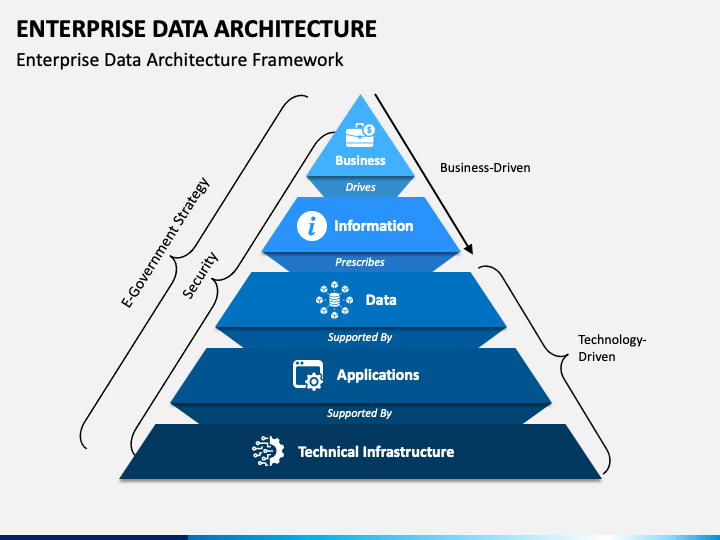
What Is Data Architecture?

Data Architecture is the discipline of designing how data is collected, stored, integrated, managed, and accessed across an organization. It defines:
- Data models and schemas (conceptual, logical, physical)
- Storage solutions (databases, data lakes, data warehouses)
- Data flow and integration patterns (ETL, ELT, streaming)
- Governance policies (quality, security, lineage, compliance)
- Access layers (APIs, query engines, BI tools)
Why Data Architecture Matters
- Enables Accurate Analysis
• Well-structured data ensures analysts and data scientists work with clean, consistent datasets - Accelerates Time-to-Insight
• Efficient pipelines and optimized storage reduce query times from hours to seconds - Supports Scalability
• Architectures designed for growth handle increasing volumes, velocity, and variety - Ensures Compliance and Security
• Centralized governance enforces privacy regulations (GDPR, CCPA) and access controls - Reduces Technical Debt
• Thoughtful design prevents the “spaghetti architecture” that plagues legacy systems
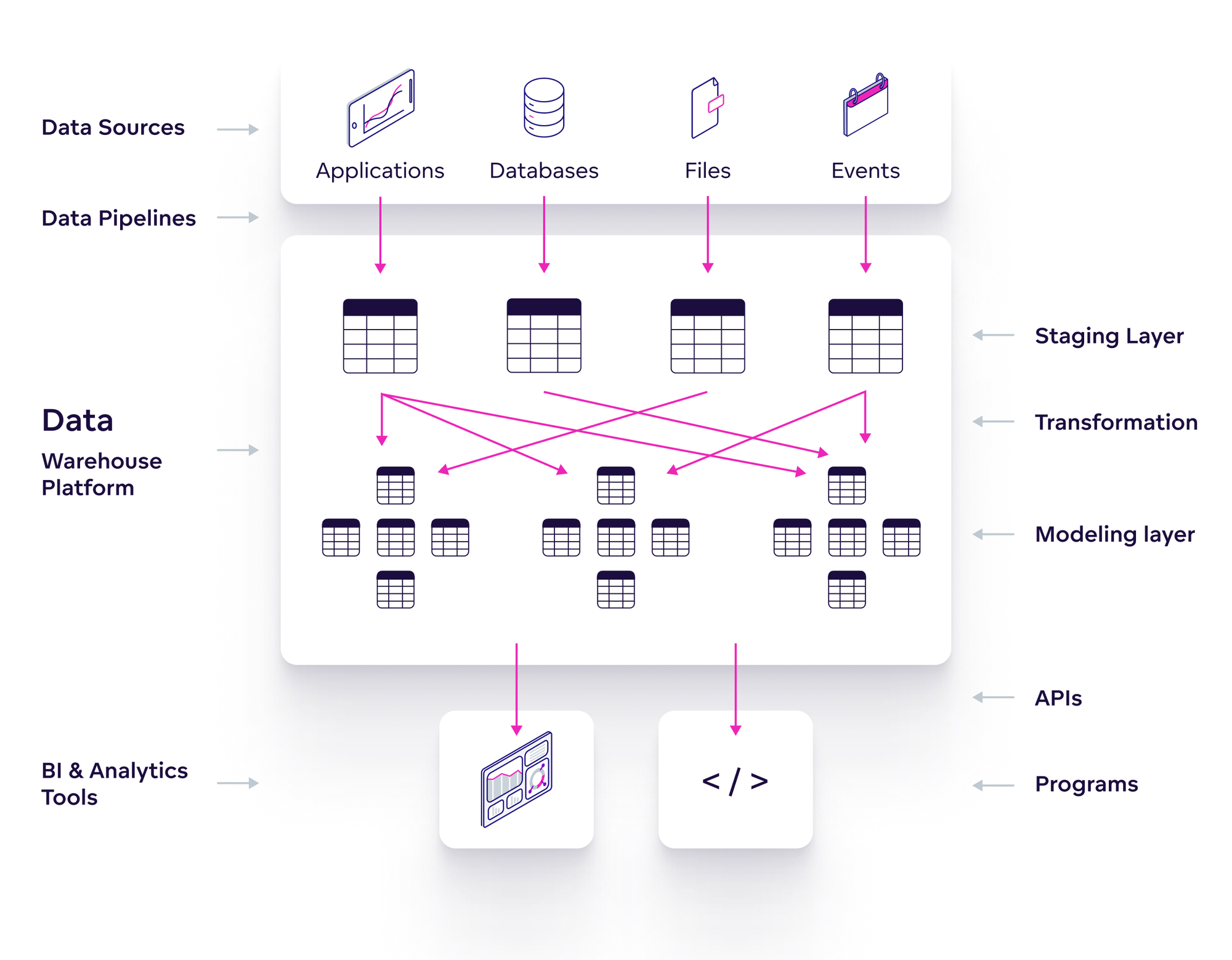
Core Components of Modern Data Architecture
1. Data Sources
- Operational Systems: CRM, ERP, e-commerce platforms
- External Data: APIs, third-party vendors, public datasets
- IoT and Sensors: Real-time streams from devices
- Logs and Events: Application telemetry, clickstreams
2. Data Ingestion Layer
- Batch ETL/ELT: Scheduled jobs using tools like Apache Airflow, dbt, or Azure Data Factory
- Real-Time Streaming: Kafka, Kinesis, Pub/Sub for event-driven architectures
- Change Data Capture (CDC): Capture incremental updates from transactional databases
3. Data Storage Layer
- Data Warehouse: Structured, optimized for SQL analytics (Snowflake, BigQuery, Redshift)
- Data Lake: Raw, semi-structured, and unstructured data (S3, ADLS, GCS)
- Lakehouse: Unified architecture combining warehouse performance with lake flexibility (Databricks, Delta Lake)
- Operational Data Store (ODS): Near-real-time integration layer for operational reporting
4. Data Processing and Transformation
- Batch Processing: Spark, Hadoop for large-scale transformations
- Stream Processing: Flink, Spark Streaming for real-time aggregations
- Data Transformation Tools: dbt, Dataform for SQL-based modeling
5. Data Serving Layer
- BI and Visualization: Tableau, Power BI, Looker for dashboards
- Data APIs: REST or GraphQL endpoints for application integration
- ML Feature Stores: Centralized repositories for model features (Feast, Tecton)
6. Data Governance and Metadata
- Data Catalog: Searchable inventory with lineage and documentation (Alation, Collibra)
- Quality Monitoring: Automated checks for completeness, accuracy, and freshness
- Access Control: Role-based permissions and audit logs
Architectural Patterns That Work
1: Lambda Architecture
- Combines batch and real-time processing for comprehensive views
- Use Case: E-commerce platforms needing both historical trends and live inventory
2: Kappa Architecture
- Stream-first approach; all data treated as events
- Use Case: Financial services requiring low-latency fraud detection
3: Data Mesh
- Decentralized, domain-oriented ownership with federated governance
- Use Case: Large enterprises with siloed business units needing autonomy
4: Hub-and-Spoke
- Central data warehouse fed by multiple source systems
- Use Case: Mid-sized companies consolidating reporting from disparate tools
5: Medallion Architecture (Bronze-Silver-Gold)
- Progressive refinement: raw → cleansed → aggregated
- Use Case: Organizations adopting lakehouse platforms like Databricks
Real Lessons from My Data Architecture Journey
Lesson 1: Start with Business Questions, Not Technology
• Built a fancy data lake but realized analysts still couldn’t answer “What’s our customer churn rate?”
Fix: Mapped use cases first, then designed architecture to support them.
Lesson 2: Data Quality Beats Data Volume
• Ingested millions of rows with inconsistent timestamps and null values—garbage in, garbage out.
Fix: Implemented validation rules at ingestion and automated quality scorecards.
Lesson 3: Documentation Is Non-Negotiable
• Six months after launch, no one remembered what “customer_id_v2” meant.
Fix: Adopted a data catalog with mandatory field descriptions and lineage tracking.
Lesson 4: Optimize for Analyst Productivity
• Data scientists spent 80% of their time wrangling data instead of modeling.
Fix: Created curated, analysis-ready datasets (gold layer) with clear SLAs.
Lesson 5: Governance Can’t Be an Afterthought
• A compliance audit revealed PII exposed in unsecured S3 buckets.
Fix: Embedded data classification, encryption, and access reviews into the architecture.
Pro Tips for Building Effective Data Architecture
- Embrace Modularity
Design loosely coupled components so you can swap tools without rewriting everything. - Prioritize Data Lineage
Track data from source to dashboard so you can debug issues and ensure trust. - Automate Everything
Use Infrastructure as Code (Terraform, Pulumi) and CI/CD for data pipelines. - Plan for Failure
Implement retry logic, dead-letter queues, and alerting for pipeline failures. - Balance Centralization and Decentralization
Central standards with domain autonomy (data mesh principles) often work best. - Invest in Metadata Management Early
It’s harder to retrofit a catalog than to build it from day one. - Optimize Costs Continuously
Partition data, compress files, and archive cold data to cloud storage tiers.
Overcoming Common Data Architecture Challenges
- Siloed Data Sources
Solution: Implement a unified ingestion framework and centralized metadata repository. - Schema Drift
Solution: Use schema registries (Confluent Schema Registry, AWS Glue) and versioning. - Performance Bottlenecks
Solution: Partition large tables, use columnar formats (Parquet, ORC), and cache frequently accessed data. - Lack of Stakeholder Buy-In
Solution: Demonstrate quick wins with pilot projects and involve business users in design. - Complexity Overload
Solution: Start simple (MVP architecture) and evolve incrementally based on real needs.
Future Trends in Data Architecture
- AI-Native Architectures
Built-in vector databases and feature stores for machine learning workloads. - Real-Time by Default
Streaming becomes the primary paradigm; batch processing reserved for heavy aggregations. - Data Fabric
Intelligent, self-service layer that abstracts underlying storage and automates integration. - Decentralized Data Ownership (Data Mesh)
Domain teams own their data products with federated governance. - Automated Data Quality and Observability
ML-powered anomaly detection and auto-remediation for data pipelines. - Green Data Architecture
Energy-efficient storage, compute optimization, and carbon-aware query scheduling.
Conclusion
Data Architecture is the foundation that determines whether your Analytics initiatives thrive or Flounder. By understanding core components, adopting proven patterns, learning from real-world lessons, and following best practices, you can build architectures that deliver trustworthy, timely insights—Empowering your organization to make data-driven decisions with confidence.
Elevate Your Competence: Uncover Our Insights on Techno
Read Our Most Recent Article About Digital Channels: Engaging Users Across Platforms!

