JAKARTA, cssmayo.com – Linked Data: Building Bridges Between Disparate Information Sources has honestly been a wild ride in my tech journey! If you’ve ever wrestled with scattered spreadsheets or databases that just don’t talk to each other (like, hello hours lost updating the same info twice!), you get the struggle. Let me spill how this Techno wave of Linked Data totally changed my workflow–and can shake up yours too.
Linked Data transformed how I think about information. For years, I struggled with data silos, incompatible systems, and integration nightmares that consumed budgets and delivered fragile solutions. Then I discovered Linked Data—a set of principles and practices for publishing and connecting structured data on the web. What seemed like an academic concept became my most powerful tool for solving real-world data integration challenges. Linked Data doesn’t just connect databases; it creates an interconnected web of knowledge where information from disparate sources seamlessly combines to answer questions no single system could address alone.
Understanding Linked Data
What Is Linked Data?
Linked Data is a method of publishing structured data so it can be interlinked and become more useful through semantic queries. Tim Berners-Lee defined four fundamental Linked Data principles:
- Use URIs as names for things: Every entity gets a unique, global identifier
- Use HTTP URIs: Identifiers should be web-accessible and dereferenceable
- Provide useful information using standards: Return structured data using RDF or JSON-LD
- Include links to other URIs: Enable discovery of related information
These simple Linked Data principles create powerful network effects. Each dataset becomes a node in a global information graph, with links forming connections that enable traversing between previously isolated information sources.
Why Linked Data Matters
Traditional data integration approaches force uniformity—everything must conform to a single schema. This works in controlled environments but fails when integrating diverse, evolving sources. Linked Data embraces heterogeneity, allowing different systems to maintain their native structures while establishing meaningful connections.
The business case for Linked Data includes reduced integration costs, improved data discovery, enhanced analytics capabilities, and future-proof architecture. Organizations implementing Linked Data report 40-60% reductions in integration maintenance costs compared to traditional ETL approaches.
My Linked Data Journey
The Problem That Started Everything
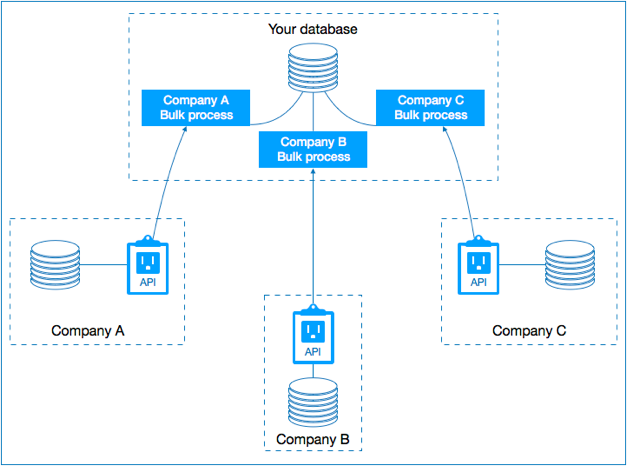
My Linked Data awakening came during a pharmaceutical research project. Scientists needed to connect clinical trial data, genomic databases, drug interaction information, and published literature—five different systems with incompatible data models. Traditional integration would require building custom connectors for each source pair, creating a maintenance nightmare.
We implemented a Linked Data approach instead. Each system published its data using standard vocabularies and included links to related entities. A clinical trial linked to genomic markers, which linked to drug compounds, which linked to research publications. Suddenly, researchers could ask questions spanning all sources without anyone building explicit integrations between them.
That project taught me Linked Data’s fundamental advantage: connections emerge from shared identifiers rather than hard-coded integrations. When new data sources joined, they simply linked to existing entities—no pipeline rewrites required.
Early Mistakes and Breakthroughs
My first Linked Data implementations were technically correct but practically unusable. I created perfect URIs, impeccable RDF, and comprehensive ontologies. Users found it incomprehensible. The breakthrough came when I stopped treating Linked Data as an end-user technology and started using it as integration infrastructure.
I built familiar interfaces—search boxes, dashboards, reports—powered by Linked Data backends. Users got better results without knowing Linked Data existed. This taught me that Linked Data succeeds when it’s invisible, providing value without requiring users to understand its technical details.
Core Linked Data Concepts
URIs: Global Identifiers
URIs (Uniform Resource Identifiers) are Linked Data’s foundation. Unlike database IDs that only have meaning within a single system, URIs provide globally unique identifiers. When different systems use the same URI for an entity, they’re explicitly stating they’re discussing the same thing.
I follow these URI design principles for Linked Data:
Use HTTPS: Security and trust matter Include domain you control: Ensures long-term stability Make them human-readable: Aids debugging and adoption Avoid implementation details: URIs should outlive specific technologies Use consistent patterns: Predictability helps developers
For example: https://example.org/person/john-smith rather than https://example.org/db/table/person/id/12345
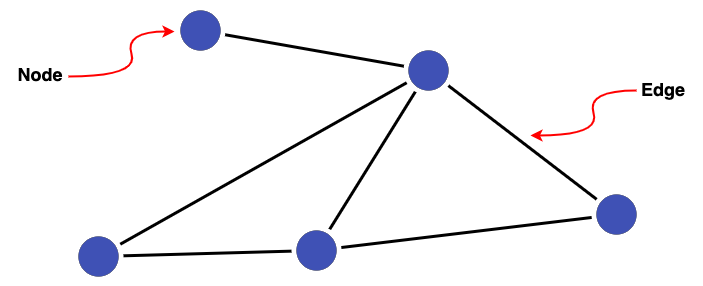
RDF: The Data Model
RDF (Resource Description Framework) structures Linked Data as subject-predicate-object triples forming a graph. This simple model offers remarkable flexibility:
<https://example.org/person/john> <http://xmlns.com/foaf/0.1/knows> <https://example.org/person/jane>
<https://example.org/person/john> <http://xmlns.com/foaf/0.1/name> "John Smith"
RDF’s advantages for Linked Data include schema flexibility (adding properties doesn’t break existing data), natural relationship representation, seamless merging of datasets, and distributed architecture enabling decentralized publishing.
Vocabularies and Ontologies
Shared vocabularies enable Linked Data interoperability. Instead of inventing proprietary schemas, I reuse established vocabularies:
Schema.org: General web content markup Dublin Core: Metadata and documentation FOAF (Friend of a Friend): Social networks and people SKOS: Taxonomies and classification systems DCAT: Dataset catalogs
Using standard vocabularies means my Linked Data automatically interoperates with other systems using the same standards. When domain-specific vocabularies don’t exist, I create minimal extensions rather than comprehensive custom ontologies.
Content Negotiation
Linked Data URIs should serve both humans and machines. I implement content negotiation so the same URI returns HTML for browsers and RDF for applications. This dual-purpose approach makes Linked Data accessible to all audiences while maintaining the principle that URIs identify things, not documents.
Building Linked Data Systems
Publishing Linked Data
I’ve published Linked Data from various sources: relational databases, NoSQL stores, APIs, and flat files. My typical workflow:
Step 1: Identify Entities Determine what things deserve URIs. Not every database row needs to be Linked Data—focus on entities others might reference.
Step 2: Design URI Patterns Create consistent, meaningful URI structures for different entity types.
Step 3: Map to Vocabularies Match your data properties to standard vocabulary terms, extending only when necessary for Linked Data compatibility.
Step 4: Generate RDF Transform source data to RDF using tools like D2RQ for databases, RML for complex mappings, or custom scripts for specialized sources.
Step 5: Implement Dereferencing Ensure URIs return useful information when accessed, making your Linked Data discoverable.
Step 6: Add External Links Connect your entities to external Linked Data sources, creating the “linked” in Linked Data.
Consuming Linked Data
Consuming Linked Data involves discovering, retrieving, and integrating information from multiple sources. I use several approaches:
SPARQL Queries: Query Linked Data endpoints using SPARQL, the standard query language. Federated queries can span multiple endpoints simultaneously.
URI Dereferencing: Follow links from one Linked Data source to another, discovering information through traversal.
Linked Data Fragments: Efficient approach for querying large Linked Data datasets without overloading servers.
Data Dumps: Download complete Linked Data datasets for local processing when appropriate.
I typically combine approaches—using SPARQL for targeted queries while maintaining local caches of frequently accessed Linked Data for performance.
Integration Patterns
Linked Data enables integration patterns impossible with traditional approaches:
Federated Queries: Query across multiple Linked Data sources as if they were a single database, without physically consolidating data.
Progressive Enhancement: Start with one Linked Data source, then enrich with additional sources as needed, adding value incrementally.
Serendipitous Reuse: Discover unexpected connections when different Linked Data publishers independently link to the same entities.
Decentralized Publishing: Multiple organizations publish Linked Data independently without central coordination, yet information remains interoperable.
Conclusion
Linked Data fundamentally changed how I approach data integration. Rather than forcing uniformity through brittle ETL pipelines, Linked Data creates flexible connections that accommodate diversity and evolve gracefully. The principles are simple—use URIs, provide structured data, include links—but the implications are profound.
Success with Linked Data requires balancing technical rigor with pragmatic implementation. Start small, focus on high-value use cases, reuse existing vocabularies, and prioritize external links that multiply your data’s value. Most importantly, remember that Linked Data is infrastructure, not end-user technology—its success is measured by the applications it enables, not by how many people understand RDF.
Organizations mastering Linked Data gain unprecedented ability to integrate disparate information sources, discover unexpected connections, and build intelligent systems that reason across previously isolated data silos. In an increasingly connected world, Linked Data provides the foundation for truly interoperable information systems.
Elevate Your Competence: Uncover Our Insights on Techno
Read Our Most Recent Article About Cyber Resilience: Building Robust Defenses Against Digital Threats!